
UNIX Awk command examples – Part 1
In this tutorial, we will discuss about UNIX awk command. Awk is a very powerful command in UNIX which is very useful while doing complex scripting and file processing. This command can be used for processing a file on a row level or on a column level or both. This command can also be used to extract particular columns or rows of any file. Awk command can match a pattern in file, can output the rows containing those records and is also able to perform some operations on the output.
Below I have tried to explain some common and mostly used UNIX awk command examples. Let us consider a simple UNIX text file on which we will be running our commands. This is a very basic file having product and sales related data. First column is the product id, second is the product name and third represents the sale value of that product. We have named this file as new_file.
This is the Part-1 of the tutorial. I will publish further parts later.
File:
prod_id,prod_name,sales
p1,pen,5,
p2,pencil,10
p1,pen,11
p3,book,6
p3,book,30
p2,pencil,8
p1,pen,9
p2,pencil,10
p3,book,5
1) Print specific columns: Display only the product_id from the above file
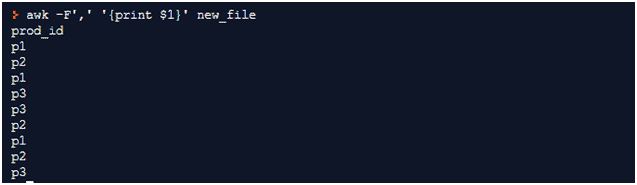
Write command name awk. -F’,’ specifies the column separator of the file
In quotes, we will mention the column no of the column that we want to print preceded by $ sign. Since product_id is the first column, hence we mention $1. (To access a column, we have to use $ and column no)
After the quote, mention the file name
In the output you will notice that product_id values are repeated. This is because the command took product_id from all the rows. To get distinct values, use sort after the above command:

2) Display product id and product name from the file

The explanation is same as above. Here also if you don’t use sort-u, then you will get repeating values from all the rows.
3) In the above output column separator is removed in the output. How to put column separator in the output also?

Here we used OFS which means Output Field separator and assigned a value to which will be the column separator in output.
4) Display sum total of all the sales values. Here we want to sum the values of third column, sales for all the rows:

Here we have used a variable sum and assigned value 0. Note that this assignment is preceded by the keyword BEGIN. This means that ‘sum=0’ part will be the first step and will be executed only once. The next part ‘sum+=$3’ or ‘sum=sum+$3’ will be executed for every row. Hence sum will be incremented by the value of the sale for each row. Once all the rows are traversed, and then END part will be executed at last and only once. This will print the sum of sales.
You can also mention some text in the output if you want like this:

5) Sum of a column based on other column/ aggregated sum/ group by operation. What is we want to know the sum of sales for each product individually:

a[$1]+=$3 – here we have summed up the sales based on product_id. We have tried to create an array of products (first column – $1) which sums up the sales (third column – $3) for the products individually. Once all the summation is done, at the END, for loop prints the product and their total sales one by one. ‘i’ represents the product id and ‘a[i]’ represents total sales for that product.
We can display product names also using below command:

6) To extend the above command, assume that we have another column in the file at last ‘quantity, and we want to sum that column also for the products individually
Example file:
prod_id,prod_name,sales,quantity
p1,pen,5,3
p2,pencil,10,4
p1,pen,11,5
p3,book,6,8
p3,book,30,9
p2,pencil,8,2
p1,pen,9,5
p2,pencil,10,77
p3,book,5,43
Here we just tried to put one more array ‘b[i]’ which holds the sum of fourth column ‘quantity’.

7) Print those record which contain some particular value for any other column. Let’s assume that you just want to print those records where product_name=’pen’. Use below command:
Here we have used comparison operator, ==, on column two and checked for value=”pen”. Note that inside print function, we have used ‘$0’. ‘$0’ will print all the columns of a file (complete row). You can choose specific column also if you want.

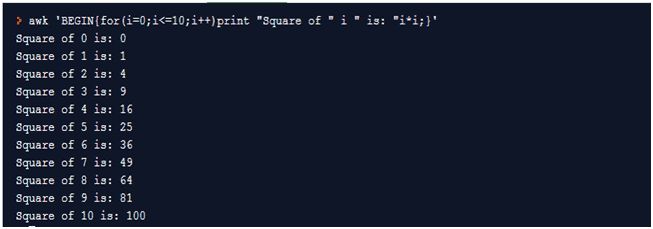
8) Example of for loop. Let’s try to print the squares for first natural numbers. Here we are just running a for loop. We are not using a file hence no delimiter value and file name. Complete command/expression has to be executed in all iterations; hence complete expression is written as part of BEGIN clause.
9) Record count of a file using awk command:
We can skip delimiter part since we are counting records.

NR=Number of Rows/Records. Try to check what happens if we don’t use END keyword.
10) Check number of columns in a file
This command is executed on the file having ‘quantity’ column also. Hence output will show 4 columns. Here we should mention delimiter otherwise command cannot identify different columns and in that case, complete row will be taken as one column.

NF=Number of Fields. Again try to remove END keyword and run the command and see what happens.
(If you want to practice above commands, then use this terminal:
https://repl.it/repls/SlowFlatCollaborativesoftware)
One thought on “UNIX Awk command examples – Part 1”
This is really awesome.. keep posting.