
Diff command in UNIX
In this session, we will be looking at the use of diff command in UNIX. While on a higher level, we know that diff command in UNIX is used to compare two files but very few would have tried to understand the actual meaning of the output of diff command. Also, note that diff command compares the file row-by-row. First row of first file with first row of second file and so on.
Actually when you run diff command, diff file1 file2, the output actually says how to make file1 look similar to file2. We will try to understand this with some examples. We will also see what other options are available with diff command.
Consider that we have below two files. These are very basic files and do not contain too much data. We will just see how diff works on these files:
file1:
a
b
c
d
e
file2:
e
a
b
r
f
Before we jump to our examples directly, I would like to tell you that in the output, you would see any of the three characters:
a-add
d-delete
c-change
1) diff file1 file2: Lets first run the most basic version of diff command in UNIX

The output clearly means that the two files are not same. But what is the meaning of the output, let’s try to understand. As I mentioned earlier, the output of the command says how to make file1 look similar to file2.
- First line says 0a1 – This means that at 0th record of first file (means at start of the first file); add a record whose value is equal to 1st record of second file.
- Second line says >e – This shows the actual value of the 1st record of second file to be added at start of first file
- Third line says 3,5c4,5 – This means 3rd to 5th record of first file needs to be changed/replaced with 4th and 5th record of second file
- <c <d <e – This means that records with values c, d, e in first file
- >r >f – needs to be replaced with records having values r and f of second file
- — – This just separates records of first file with second file
- Line numbers coming prior to characters a/c/d are records of first file. And numbers after the character are records of second file
- >- This means that record of second file
- < – This means records of first file
In short, first add a record ‘e’ at the beginning of the first file. Then replace records 3,4,5 of first file with records 4,5 of second file. Once these two things are completed, file1 will look similar to file2. (Try out different examples to see how diff command reacts on two files)
2) diff –i file1 file2: Case in-sensitive comparison
By default, diff considers upper/lower case while comparing. If you want to ignore the case, we have to use –i. Let’s consider below two files. The case is different in both the files.
f1:
Pen
f2:
pen
Running diff command with –i does not give any difference.

Let’s see what happens if we run diff without –i. As we discussed above, it says that 1st record of first file needs to be changed/replaced with 1st record of second file to make both files same

3) diff –c file1 file2: This command shows the difference in both the files by putting ‘!’ before un-matching records. +/- are used to show records to be added or deleted. Let’s run this command on our previous files: file1 and file2
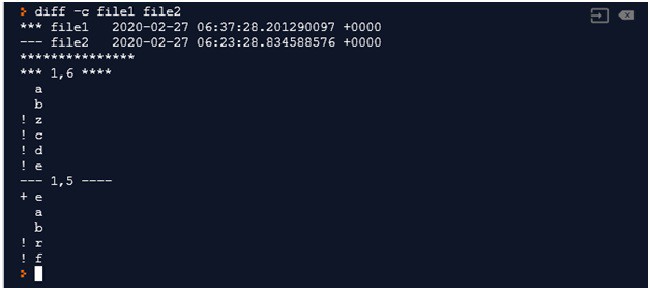
- First two lines shows the file creation time of both the files. *** is put before first file details and — is placed before details of second file
- a b – Since there are no signs before these two values, it means that these two records are present in both the files.
- Then we can see ‘!’ sign for records z,c,d,e – This means that these four records are different that the second file. The catch here is e is present in both the files then why ‘!’ is present with e. See next statement for this confusion
- +e – This means that record e is added to the second file at top. That’s why above e is shown with ‘!’
- a,b – these are present in both the files
- !r, !f – This means that r and f are not present in first file, these are the different records
- diff –p will also give the same output
4) diff –y file1 file2: Tabular display of differences in the files. See the second column of the output.
- >e – This means that this is extra row in second file
- a b – These are present in both the files
- |r |f – These are the different rows in second file when compared with first file
- <d <e – This means the d and e are extra records in first file.

diff –y –W70 file1 file2: This command will just make the width between two columns of above tabular output to 70 characters. Remaining output is same.
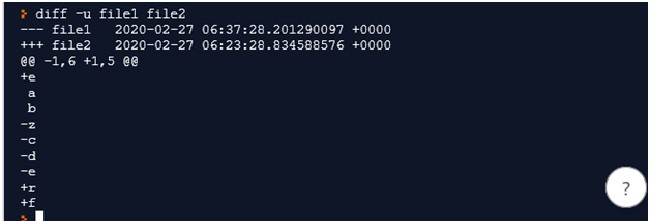
5) diff –u file1 file2: This is another way to show how to make file1 look same as file2 using + and – signs
- +e – means that add ‘e’ at start of the first file
- a b- remains same
- -z –c –d –e – Remove these four records
- +r +f – Add records r and f
- Doing these changes will make file1 same as file2
6) diff –b file1 file2: This is used to compare formatted as well as un-formatted files. The output is no different than the first command of this session.
7) diff –w file1 file2: This is used to compare two file by ignoring all spacing variations. Let’s come again to our second set of files. The case is same in both the files. However, try to look closely and you would notice one space before ‘p’ in second file
f1:
pen
f2:
pen
If you run diff command without –w option, then you will see that files are different. But running with -w will show that files are same:

Other UNIX sessions:
UNIX Grep Command
UNIX Awk Command